Preprocessing and clustering#
import anndata as ad
import pooch
import scanpy as sc
sc.set_figure_params(dpi=50, facecolor="white")
The data used in this basic preprocessing and clustering tutorial was collected from bone marrow mononuclear cells of healthy human donors and was part of openproblem’s NeurIPS 2021 benchmarking dataset [LBC+21]. The samples used in this tutorial were measured using the 10X Multiome Gene Expression and Chromatin Accessability kit.
We are reading in the count matrix into an AnnData object, which holds many slots for annotations and different representations of the data.
def download_sample(sample_id: str, known_hash: str) -> ad.AnnData:
path = pooch.retrieve(
path=pooch.os_cache("scverse_tutorials"),
url=f"https://exampledata.scverse.org/tutorials/neurips-2021/{sample_id}_filtered_feature_bc_matrix.h5",
known_hash=known_hash,
)
sample_adata = sc.read_10x_h5(path)
sample_adata.var_names_make_unique()
return sample_adata
samples = {
"s1d1": "md5:a99285913ea3f3d22600d3d2f8a88e34",
"s1d3": "md5:825f7f7578e3dc0b8955f5a97a402338",
}
adatas = {id_: download_sample(id_, known_hash) for id_, known_hash in samples.items()}
adata = ad.concat(adatas, label="sample")
adata.obs_names_make_unique()
The data contains 8,785 cells and 36,601 measured genes. This tutorial includes a basic preprocessing and clustering workflow.
Quality Control#
The scanpy function calculate_qc_metrics() calculates common quality control (QC) metrics, which are largely based on calculateQCMetrics from scater [MCLW17]. One can pass specific gene population to calculate_qc_metrics() in order to calculate proportions of counts for these populations. Mitochondrial, ribosomal and hemoglobin genes are defined by distinct prefixes as listed below.
# mitochondrial genes
adata.var["mt"] = adata.var_names.str.startswith("MT-") # "MT-" for human, "Mt-" for mouse
# ribosomal genes
adata.var["ribo"] = adata.var_names.str.startswith(("RPS", "RPL"))
# hemoglobin genes
adata.var["hb"] = adata.var_names.str.contains("^HB[^(P)]")
sc.pp.calculate_qc_metrics(adata, qc_vars=["mt", "ribo", "hb"], inplace=True, log1p=True)
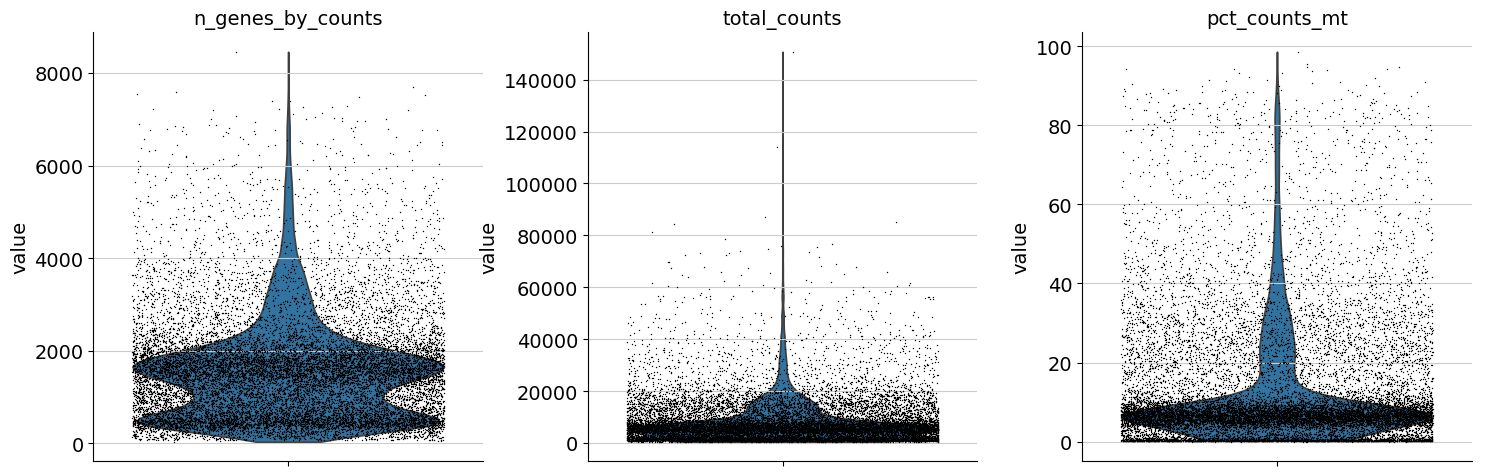
One can now inspect violin plots of some of the computed QC metrics:
the number of genes expressed in the count matrix
the total counts per cell
the percentage of counts in mitochondrial genes
sc.pl.violin(adata, ["n_genes_by_counts", "total_counts", "pct_counts_mt"], jitter=0.4, multi_panel=True)
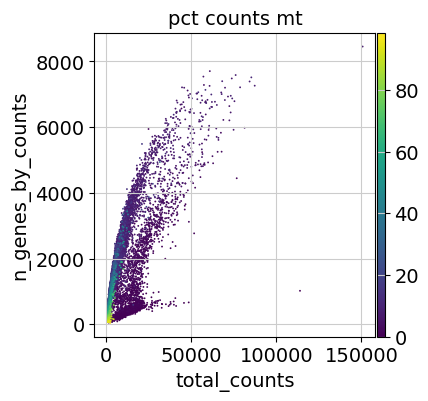
Additionally, it is useful to consider QC metrics jointly by inspecting a scatter plot colored by pct_counts_mt.
sc.pl.scatter(adata, "total_counts", "n_genes_by_counts", color="pct_counts_mt")
Based on the QC metric plots, one could now remove cells that have too many mitochondrial genes expressed or too many total counts by setting manual or automatic thresholds. However, it proved to be beneficial to apply a very permissive filtering strategy in the beginning for your single-cell analysis and filter low quality cells during clustering or revisit the filtering again at a later point. We therefore now only filter cells with less than 100 genes expressed and genes that are detected in less than 3 cells.
Additionally, it is important to note that for datasets with multiple batches, quality control should be performed for each sample individually as quality control thresholds can very substantially between batches.
sc.pp.filter_cells(adata, min_genes=100)
sc.pp.filter_genes(adata, min_cells=3)
Doublet detection#
As a next step, we run a doublet detection algorithm. Identifying doublets is crucial as they can lead to misclassifications or distortions in downstream analysis steps. Scanpy contains the doublet detection method Scrublet [WLK19]. Scrublet predicts cell doublets using a nearest-neighbor classifier of observed transcriptomes and simulated doublets. scanpy.pp.scrublet() adds doublet_score and predicted_doublet to .obs. One can now either filter directly on predicted_doublet or use the doublet_score later during clustering to filter clusters with high doublet scores.
sc.pp.scrublet(adata, batch_key="sample")
See also
Alternative methods for doublet detection within the scverse ecosystem are DoubletDetection and SOLO. You can read more about these in the Doublet Detection chapter of Single Cell Best Practices.
Normalization#
The next preprocessing step is normalization. A common approach is count depth scaling with subsequent log plus one (log1p) transformation. Count depth scaling normalizes the data to a “size factor” such as the median count depth in the dataset, ten thousand (CP10k) or one million (CPM, counts per million). The size factor for count depth scaling can be controlled via target_sum in pp.normalize_total. We are applying median count depth normalization with log1p transformation (AKA log1PF).
# Saving count data
adata.layers["counts"] = adata.X.copy()
# Normalizing to median total counts
sc.pp.normalize_total(adata)
# Logarithmize the data:
sc.pp.log1p(adata)
Feature selection#
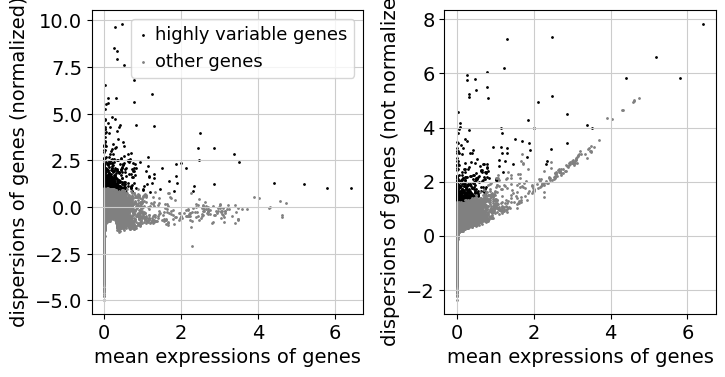
As a next step, we want to reduce the dimensionality of the dataset and only include the most informative genes. This step is commonly known as feature selection. The scanpy function pp.highly_variable_genes annotates highly variable genes by reproducing the implementations of Seurat [SFG+15], Cell Ranger [ZTB+17], and Seurat v3 [SBH+19] depending on the chosen flavor.
sc.pp.highly_variable_genes(adata, n_top_genes=2000, batch_key="sample")
sc.pl.highly_variable_genes(adata)
Dimensionality Reduction#
Reduce the dimensionality of the data by running principal component analysis (PCA), which reveals the main axes of variation and denoises the data.
sc.tl.pca(adata)
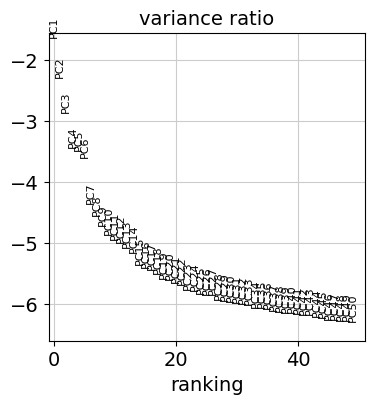
Let us inspect the contribution of single PCs to the total variance in the data. This gives us information about how many PCs we should consider in order to compute the neighborhood relations of cells, e.g. used in the clustering function leiden() or tsne(). In our experience, often a rough estimate of the number of PCs does fine.
sc.pl.pca_variance_ratio(adata, n_pcs=50, log=True)
Visualization#
Let us compute the neighborhood graph of cells using the PCA representation of the data matrix.
sc.pp.neighbors(adata)
We suggest embedding the graph in two dimensions using UMAP (McInnes et al., 2018), see below.
sc.tl.umap(adata)
We can now visualize the UMAP according to the sample.
sc.pl.umap(adata, color="sample")
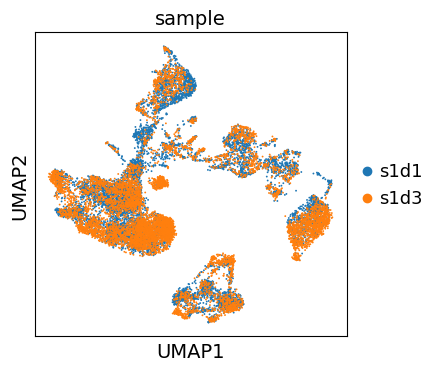
Even though the data considered in this tutorial includes two different samples, we only observe a minor batch effect and we can continue with clustering and annotation of our data.
If you inspect batch effects in your UMAP it can be beneficial to integrate across samples and perform batch correction/integration.
Clustering#
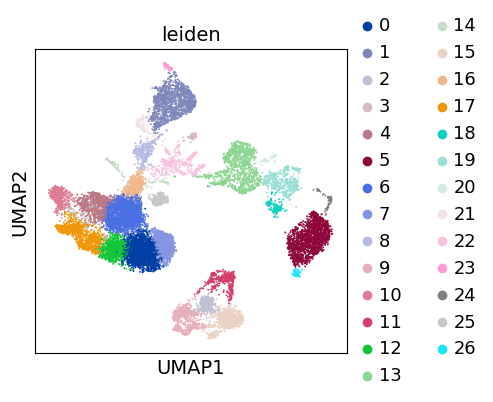
As with Seurat and many other frameworks, we recommend the Leiden graph-clustering method (community detection based on optimizing modularity) [TWVE19]. Note that Leiden clustering directly clusters the neighborhood graph of cells, which we already computed in the previous section.
sc.tl.leiden(adata, flavor="igraph")
sc.pl.umap(adata, color=["leiden"])
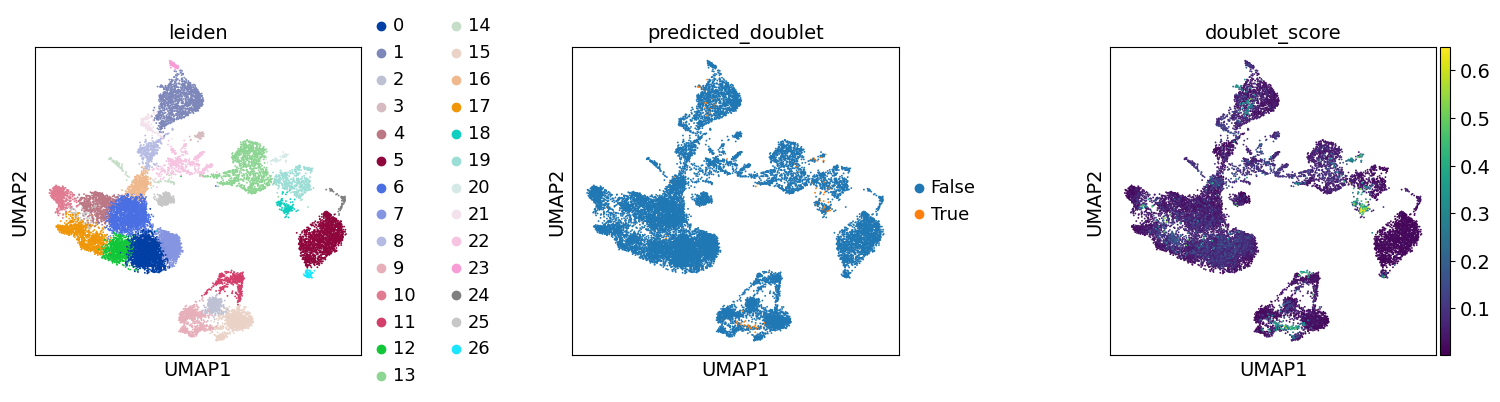
Re-assess quality control and cell filtering#
As indicated before, we will now re-assess our filtering strategy by visualizing different QC metrics using UMAP.
adata.obs["predicted_doublet"] = adata.obs["predicted_doublet"].astype("category")
sc.pl.umap(
adata,
color=["leiden", "predicted_doublet", "doublet_score"],
# increase horizontal space between panels
wspace=0.5,
)
We can now subset the AnnData object to exclude cells predicted as doublets:
adata = adata[~adata.obs["predicted_doublet"].to_numpy()].copy()
sc.pl.umap(
adata, color=["leiden", "log1p_total_counts", "pct_counts_mt", "log1p_n_genes_by_counts"], wspace=0.5, ncols=2
)
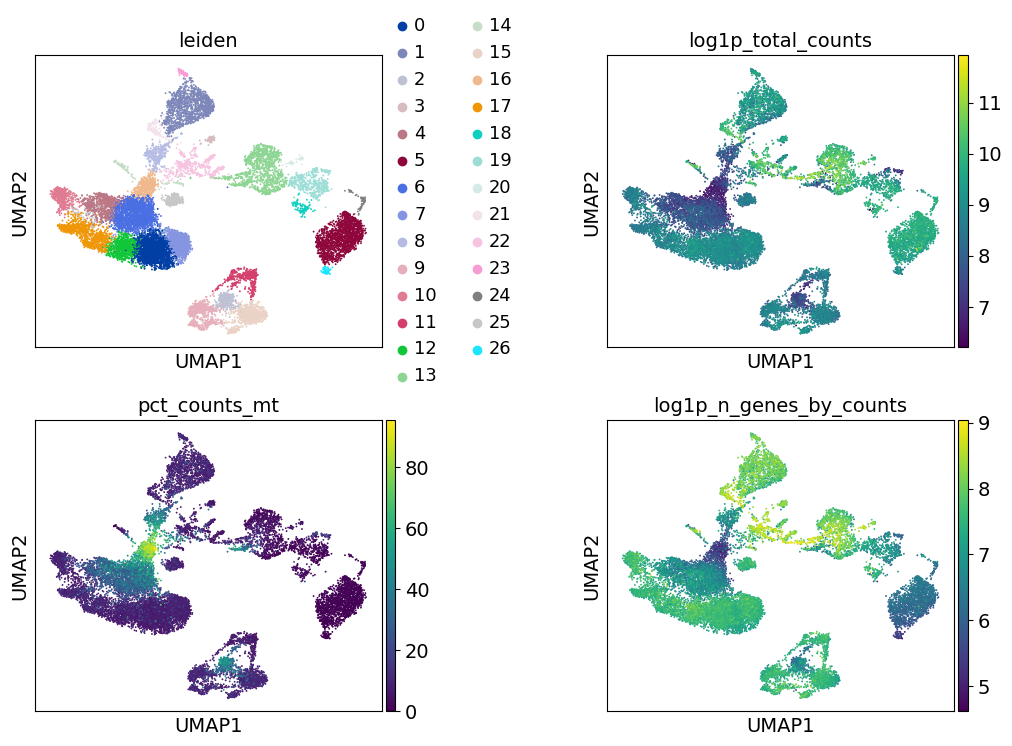
Cell-type annotation#
import celltypist as ct
import decoupler as dc
We have now reached a point where we have obtained a set of cells with decent quality, and we can proceed to their annotation to known cell types. Typically, this is done using genes that are exclusively expressed by a given cell type, or in other words these genes are the marker genes of the cell types, and are thus used to distinguish the heterogeneous groups of cells in our data. Previous efforts have collected and curated various marker genes into available resources, such as CellMarker, TF-Marker, and PanglaoDB.
Commonly and classically, cell type annotation uses those marker genes subsequent to the grouping of the cells into clusters. So, let’s generate a set of clustering solutions which we can then use to annotate our cell types. Here, we will use the Leiden clustering algorithm which will extract cell communities from our nearest neighbours graph.
sc.tl.leiden(adata, flavor="igraph", key_added="leiden_res0_02", resolution=0.02)
sc.tl.leiden(adata, flavor="igraph", key_added="leiden_res0_5", resolution=0.5)
sc.tl.leiden(adata, flavor="igraph", key_added="leiden_res2", resolution=2)
Notably, the number of clusters that we define is largely arbitrary, and so is the resolution parameter that we use to control for it. As such, the number of clusters is ultimately bound to the stable and biologically-meaningful groups that we can ultimately distringuish, typically done by experts in the corresponding field or by using expert-curated prior knowledge in the form of markers.
sc.pl.umap(
adata,
color=["leiden_res0_02", "leiden_res0_5", "leiden_res2"],
legend_loc="on data",
)
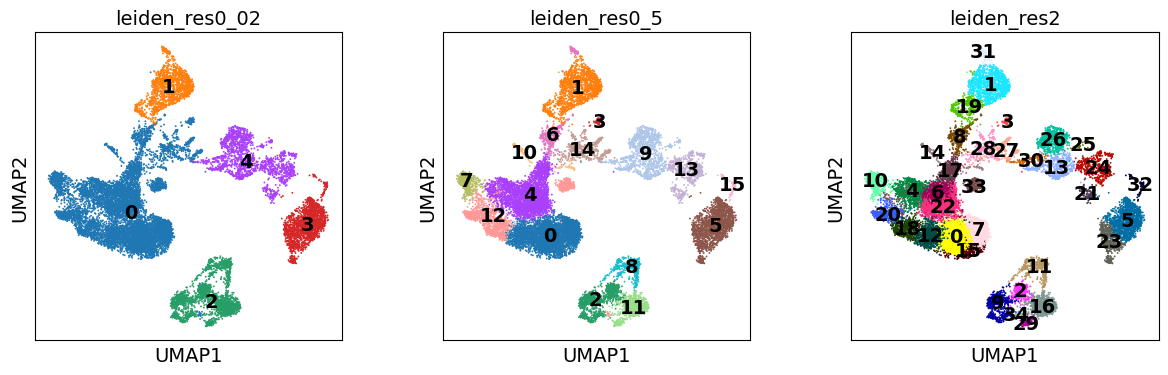
Though UMAPs should not be over-interpreted, here we can already see that in the highest resolution our data is over-clustered, while the lowest resolution is likely grouping cells which belong to distinct cell identities.
Marker gene set#
Let’s define a set of marker genes for the main cell types that we expect to see in this dataset. These were adapted from Single Cell Best Practices annotation chapter, for a more detailed overview and best practices in cell type annotation, we refer the user to it.
marker_genes = {
"CD14+ Mono": ["FCN1", "CD14"],
"CD16+ Mono": ["TCF7L2", "FCGR3A", "LYN"],
# Note: DMXL2 should be negative
"cDC2": ["CST3", "COTL1", "LYZ", "DMXL2", "CLEC10A", "FCER1A"],
"Erythroblast": ["MKI67", "HBA1", "HBB"],
# Note HBM and GYPA are negative markers
"Proerythroblast": ["CDK6", "SYNGR1", "HBM", "GYPA"],
"NK": ["GNLY", "NKG7", "CD247", "FCER1G", "TYROBP", "KLRG1", "FCGR3A"],
"ILC": ["ID2", "PLCG2", "GNLY", "SYNE1"],
"Naive CD20+ B": ["MS4A1", "IL4R", "IGHD", "FCRL1", "IGHM"],
# Note IGHD and IGHM are negative markers
"B cells": ["MS4A1", "ITGB1", "COL4A4", "PRDM1", "IRF4", "PAX5", "BCL11A", "BLK", "IGHD", "IGHM"],
"Plasma cells": ["MZB1", "HSP90B1", "FNDC3B", "PRDM1", "IGKC", "JCHAIN"],
"Plasmablast": ["XBP1", "PRDM1", "PAX5"], # Note PAX5 is a negative marker
"CD4+ T": ["CD4", "IL7R", "TRBC2"],
"CD8+ T": ["CD8A", "CD8B", "GZMK", "GZMA", "CCL5", "GZMB", "GZMH", "GZMA"],
"T naive": ["LEF1", "CCR7", "TCF7"],
"pDC": ["GZMB", "IL3RA", "COBLL1", "TCF4"],
}
def group_max(adata: sc.AnnData, groupby: str) -> str:
import pandas as pd
agg = sc.get.aggregate(adata, by=groupby, func="mean")
return pd.Series(agg.layers["mean"].sum(1), agg.obs[groupby]).idxmax()
sc.pl.dotplot(adata, marker_genes, groupby="leiden_res0_02")

Here, we can see that cluster 1 perhaps contains an admixture of monocytes and dendritic cells, while in cluster 2 we have different populations of B lymphocytes. Thus, we should perhaps consider a higher clustering resolution.
sc.pl.dotplot(adata, marker_genes, groupby="leiden_res0_5")
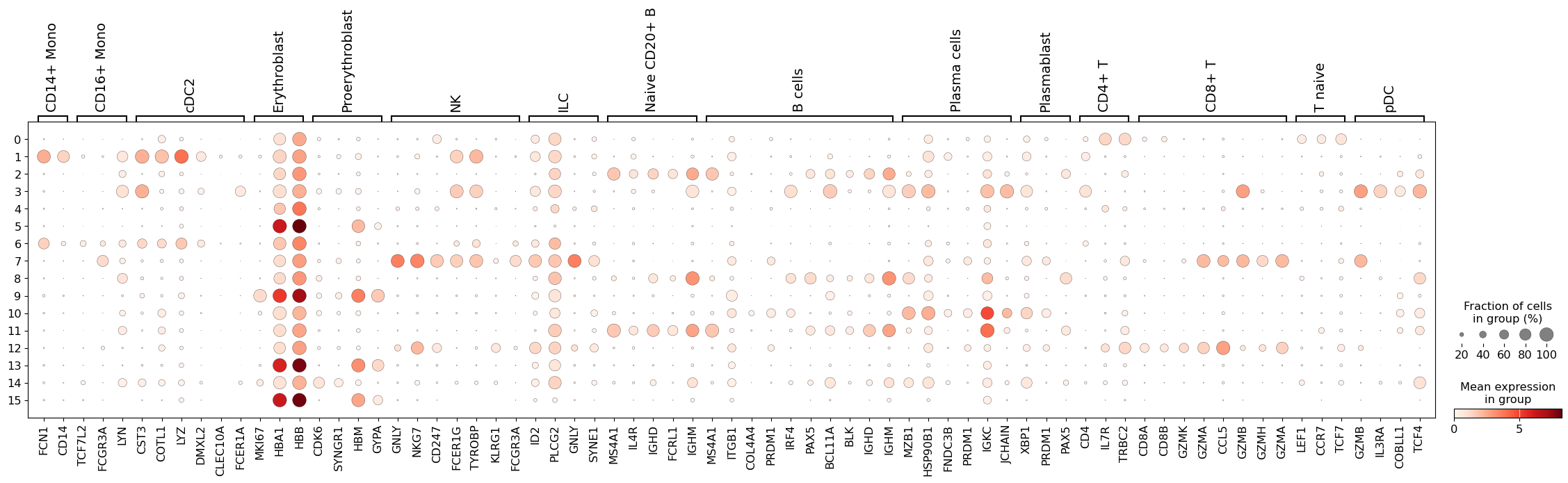
This seems like a resolution that suitable to distinguish most of the different cell types in our data. Ideally, one would look specifically into each cluster, and attempt to subcluster those if required.
Automatic label prediction#
In addition to using marker collections to annotate our labels, there exist approaches to automatically annotate scRNA-seq datasets. One such tool is CellTypist, which uses gradient-descent optimised logistic regression classifiers to predict cell type annotations.
First, we need to retrive the CellTypist models that we wish to use, in this case we will use models with immune cell type and subtype populations generated using 20 tissues from 18 studies (Domínguez Conde, et al. 2022).
ct.models.download_models(model=["Immune_All_Low.pkl"], force_update=True)
Then we predict the major cell type annotations. In this case we will enable majority_voting, which will assign a label to the clusters that we obtained previously.
model = ct.models.Model.load(model="Immune_All_Low.pkl")
predictions = ct.annotate(adata, model="Immune_All_Low.pkl", majority_voting=True, over_clustering="leiden_res0_5")
# convert back to anndata||
adata = predictions.to_adata()
Let’s examine the results of automatic clustering:
sc.pl.umap(adata, color="majority_voting", ncols=1)
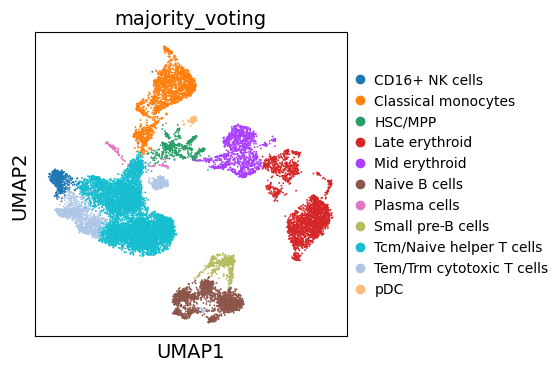
Note that our previously ‘Unknown’ cluster is now assigned as ‘Pro-B cells’.
Annotation with enrichment analysis#
Automatic cell type labelling with methods that require pre-trained models will not always work as smoothly, as such classifiers need to be trained on and be representitive for a given tissue and the cell types within it. So, as a more generalizable approach to annotate the cells, we can also use the marker genes from any database, for example PanglaoDB. Here we will use it with simple multi-variate linear regression, implemented in decoupler. Essentially, this will test if any collection of genes are enriched in any of the cells. Ultimately, this approach is similar to many other marker-based classifiers.
Let’s get canonical cell markers using with decoupler which queries the OmniPath metadata-base to obtain the PanglaoDB marker gene database with cannonical cell type markers.
# Query Omnipath and get PanglaoDB
markers = dc.op.resource(name="PanglaoDB", organism="human")
# Keep canonical cell type markers alone
markers = markers[markers["canonical_marker"]]
# Remove duplicated entries
markers = markers[~markers.duplicated(["cell_type", "genesymbol"])]
markers.head()
| genesymbol | canonical_marker | cell_type | germ_layer | human | human_sensitivity | human_specificity | mouse | mouse_sensitivity | mouse_specificity | ncbi_tax_id | organ | ubiquitiousness | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | A2M | True | Bergmann glia | Ectoderm | True | 0.0 | 0.062343 | True | 0.333333 | 0.001604 | 9606 | Brain | 0.012 |
| 4 | A4GALT | True | Mast cells | Mesoderm | True | 0.0 | 0.014133 | True | 0.000000 | 0.003023 | 9606 | Immune system | 0.005 |
| 5 | A7KBS4 | True | Embryonic stem cells | Epiblast | False | NaN | NaN | True | NaN | NaN | 10090 | Zygote | 0.000 |
| 8 | AANAT | True | Pinealocytes | Ectoderm | True | 0.0 | 0.000000 | True | 0.000000 | 0.000000 | 9606 | Brain | 0.000 |
| 9 | AANAT | True | Astrocytes | Ectoderm | True | 0.0 | 0.000000 | True | 0.000000 | 0.000000 | 9606 | Brain | 0.000 |
dc.mt.mlm(adata, net=markers.rename(columns=dict(cell_type="source", genesymbol="target")), verbose=True)
The obtained results are stored in .obsm, with "score_mlm" representing coefficient t-values, and "padj_mlm" representing adjusted p-values.:
adata.obsm["score_mlm"].head()
| Acinar cells | Adipocytes | Adrenergic neurons | Airway goblet cells | Alpha cells | Alveolar macrophages | Astrocytes | B cells | B cells memory | B cells naive | ... | Smooth muscle cells | T cells | T helper cells | T regulatory cells | Tanycytes | Taste receptor cells | Thymocytes | Trophoblast cells | Tuft cells | Urothelial cells | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AAACCCAAGGATGGCT-1 | -0.813184 | -0.520414 | -0.400053 | -0.669719 | 0.317616 | 0.897358 | 0.605177 | 1.289426 | -0.148213 | 0.636441 | ... | -0.773258 | 12.265937 | 0.624422 | -1.856662 | 0.637025 | -0.938473 | 1.988553 | 0.873108 | 1.788615 | -0.731310 |
| AAACCCAAGGCCTAGA-1 | 0.345406 | -0.010499 | -0.739360 | -0.780538 | 1.015482 | -0.255967 | 0.670266 | -0.014465 | -2.241401 | 1.402426 | ... | -1.630382 | 0.872546 | -0.493240 | -1.244801 | -0.216706 | -0.768289 | -0.666512 | -0.526527 | 2.113435 | -1.062055 |
| AAACCCAAGTGAGTGC-1 | 0.424199 | -0.004810 | -0.273429 | -0.346323 | -0.478050 | -0.964836 | -1.122095 | 3.817127 | 2.280732 | 7.948663 | ... | -0.736918 | 2.926307 | 0.996365 | -1.119694 | -0.535775 | -0.734127 | 0.901015 | 2.339273 | 1.796092 | -0.387165 |
| AAACCCACAAGAGGCT-1 | -1.410204 | -1.535592 | -0.612504 | -0.725710 | 1.084389 | 1.085159 | -1.278920 | -0.545802 | -3.780099 | 6.828738 | ... | -2.045752 | 0.107504 | -0.749522 | -1.061512 | -0.174441 | -0.561069 | 0.856537 | 0.551763 | 3.004563 | -1.005575 |
| AAACCCACATCGTGGC-1 | 1.272671 | -1.279977 | -0.217868 | -0.173188 | -0.542109 | -0.448570 | 0.416237 | 0.047668 | 0.549838 | -1.189070 | ... | -0.100301 | 1.565442 | 0.207854 | 1.978891 | -0.305805 | 1.622160 | -1.188619 | 0.037042 | 0.313956 | -0.384934 |
5 rows × 118 columns
To visualize the obtianed scores, we can re-use any of scanpy’s plotting functions. First though, we will extract them from the adata object.
acts = dc.pp.get_obsm(adata, "score_mlm")
sc.pl.umap(
acts,
color=[
"majority_voting",
"B cells",
"T cells",
"Monocytes",
"Erythroid-like and erythroid precursor cells",
"NK cells",
],
wspace=0.5,
ncols=3,
)
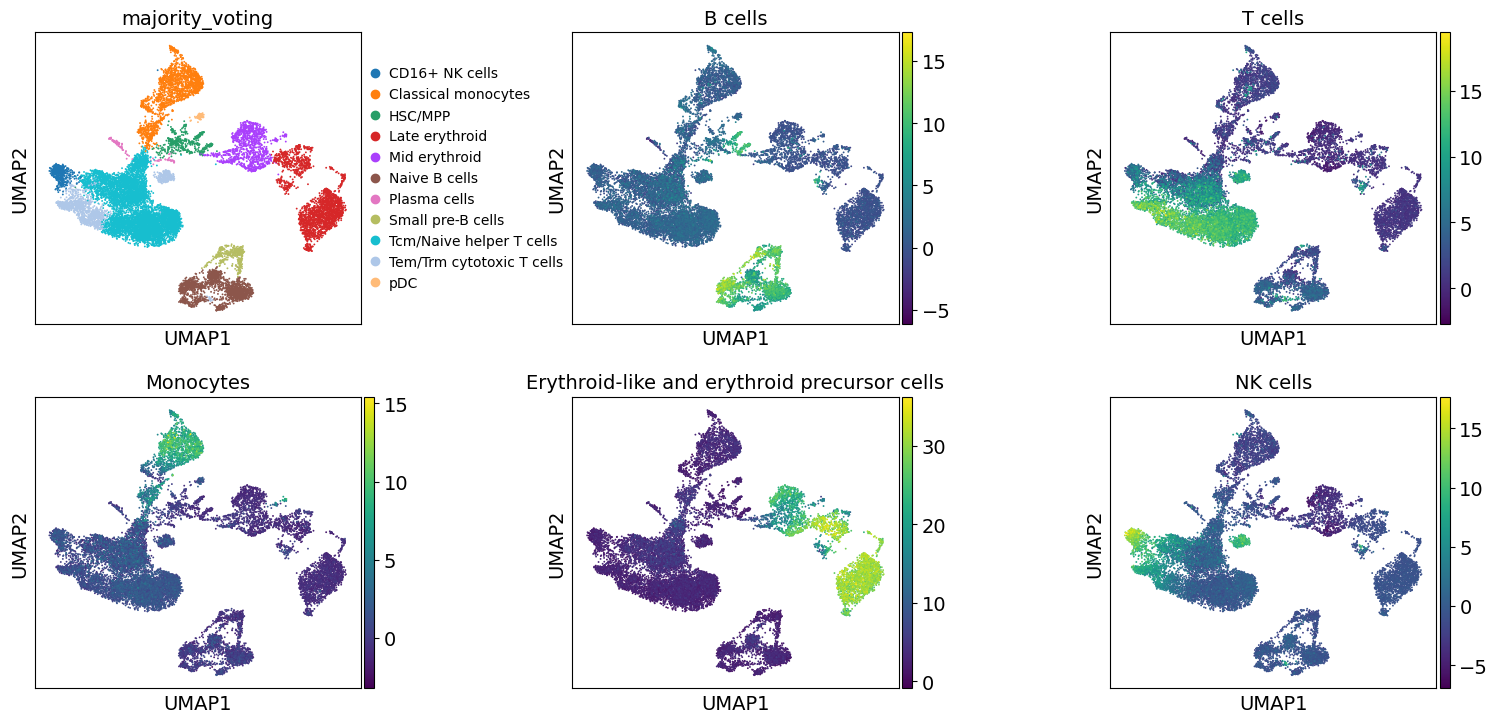
These results further confirm the our automatic annotation with Celltypist. In addition, here we can also transfer the max over-representation score estimates to assign a label to each cluster.
enr = dc.tl.rankby_group(acts, groupby="leiden_res0_5")
annotation_dict = enr[enr["stat"] > 0].groupby("group").head(1).set_index("group")["name"].to_dict()
adata.obs["dc_anno"] = [annotation_dict[clust] for clust in adata.obs["leiden_res0_5"]]
Let’s compare all resulting annotations here
sc.pl.umap(adata, color=["majority_voting", "dc_anno"], ncols=1)
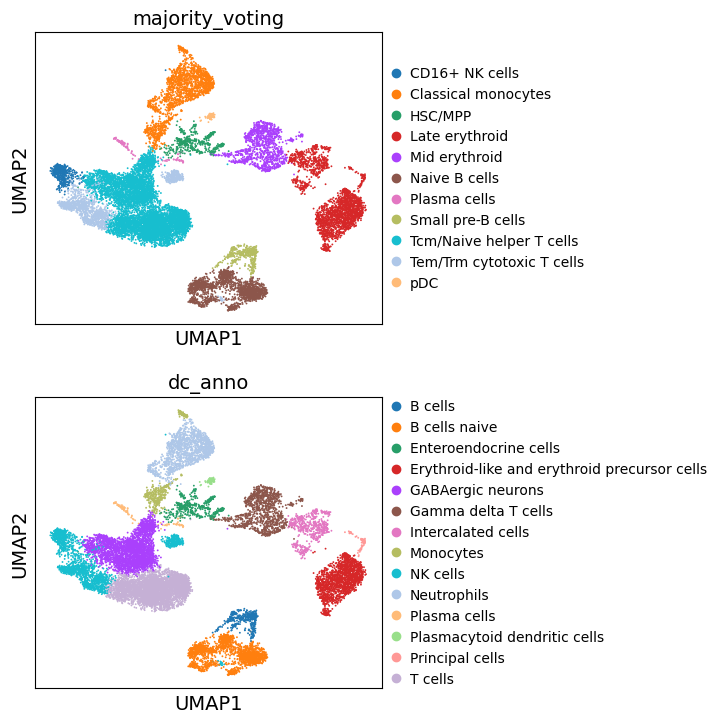
Great. We can see that the different approaches to annotate the data are largely concordant. Though, these annotations are decent, cell type annotation is laborous and repetitive task, one which typically requires multiple rounds of sublucstering and re-annotation. Nevertheless, we now have a good basis with which we can further proceed with manually refining our annotations.
Differentially-expressed Genes as Markers#
Furthermore, one can also calculate marker genes per cluster and then look up whether we can link those marker genes to any known biology, such as cell types and/or states. This is typically done using simple statistical tests, such as Wilcoxon and t-test, for each cluster vs the rest.
# Obtain cluster-specific differentially expressed genes
sc.tl.rank_genes_groups(adata, groupby="leiden_res0_5")
# Filter those
sc.tl.filter_rank_genes_groups(adata, min_fold_change=1.5)
We can then visualize the top 5 differentially-expressed genes on a dotplot.
sc.pl.rank_genes_groups_dotplot(adata, groupby="leiden_res0_5", standard_scale="var", n_genes=5)
WARNING: dendrogram data not found (using key=dendrogram_leiden_res0_5). Running `sc.tl.dendrogram` with default parameters. For fine tuning it is recommended to run `sc.tl.dendrogram` independently.
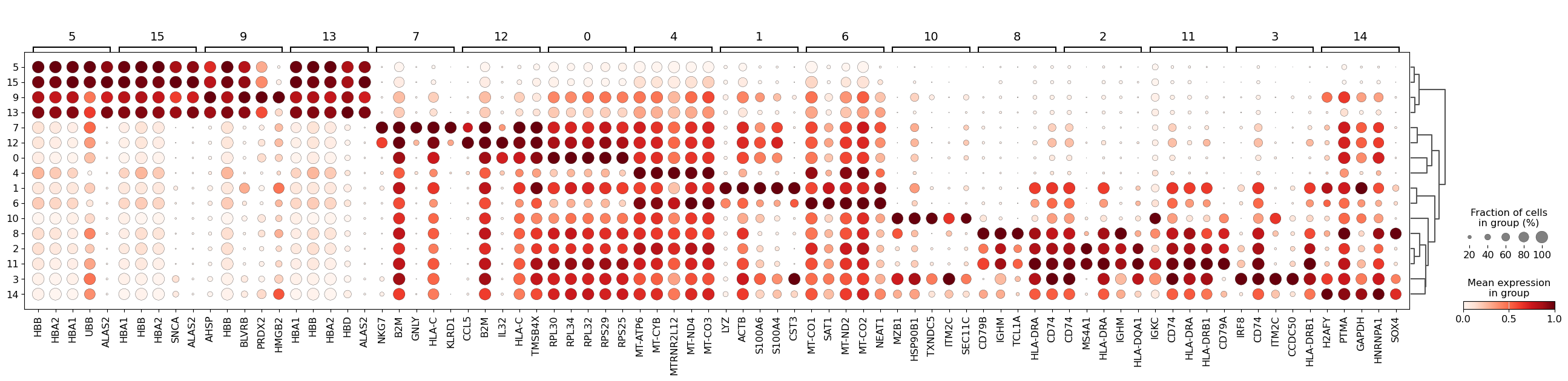
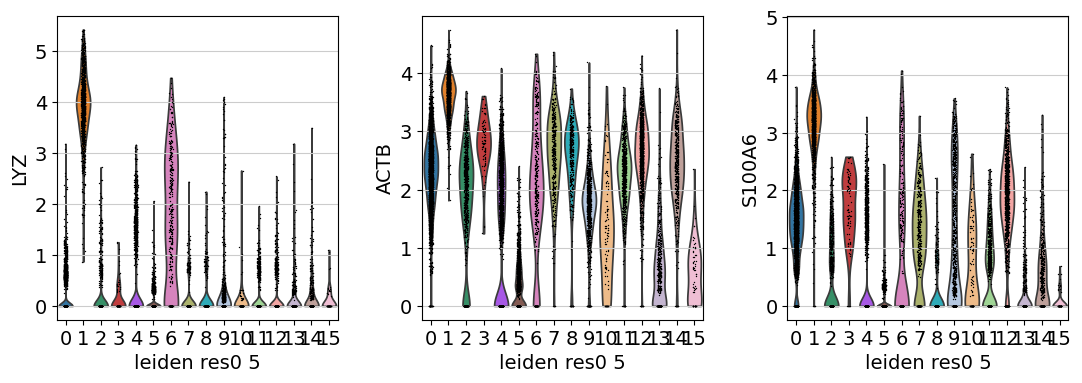
We see that LYZ, ACT8, S100A6, S100A4, and CST3 are all highly expressed in cluster 3.
Let’s visualize those at the UMAP space:
cluster3_genes = ["LYZ", "ACTB", "S100A6", "S100A4", "CST3"]
sc.pl.umap(adata, color=[*cluster3_genes, "leiden_res0_5"], legend_loc="on data", frameon=False, ncols=3)
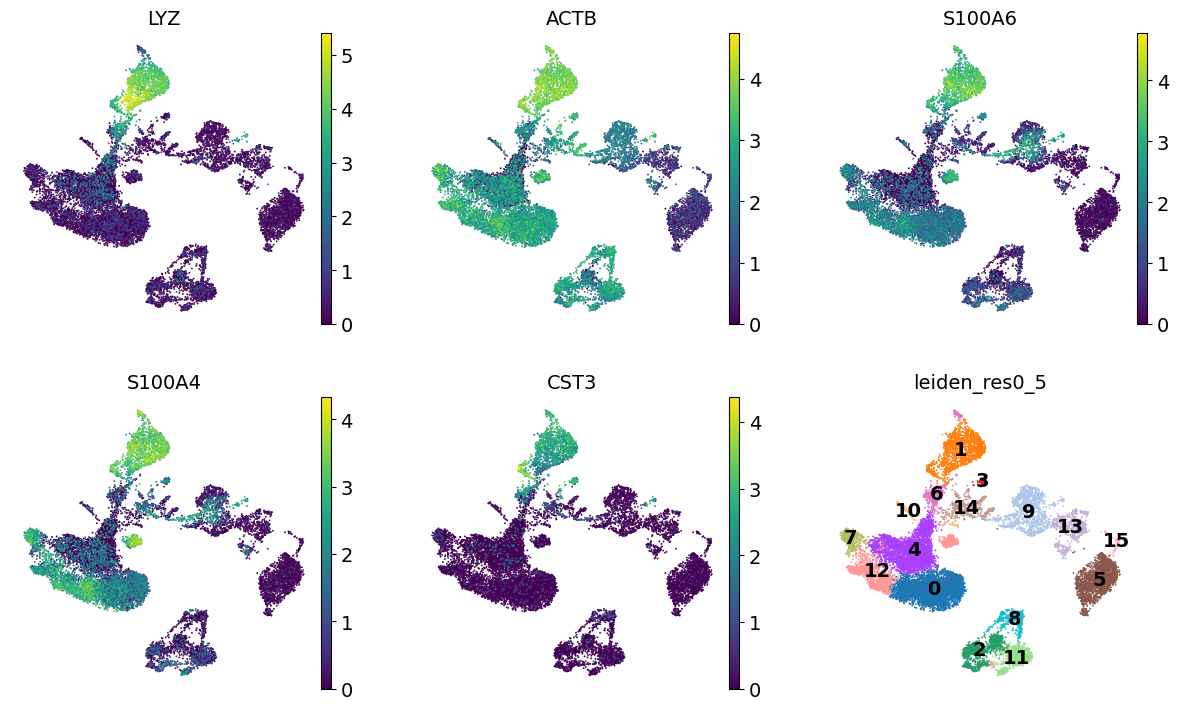
Similarly, we can also generate a Violin plot with the distrubtions of the same genes across the clusters.
sc.pl.violin(adata, keys=cluster3_genes[0:3], groupby="leiden_res0_5", multi_panel=True)